
 Op 9 mei 2014 kwam dr. John Houde, hoofd van het Speech Neuroscience Laboratory aan de University of California, San Francisco (USA) naar het Max Planck Instituut in Nijmegen om een lezing te geven over ‘spraakcontrole’. Het onderzoek van dr. Houde gaat over hoe we spraak produceren, en wat de invloed is van auditieve feedback.
Op 9 mei 2014 kwam dr. John Houde, hoofd van het Speech Neuroscience Laboratory aan de University of California, San Francisco (USA) naar het Max Planck Instituut in Nijmegen om een lezing te geven over ‘spraakcontrole’. Het onderzoek van dr. Houde gaat over hoe we spraak produceren, en wat de invloed is van auditieve feedback.
Heel wat onderzoek in de afgelopen jaren heeft aangetoond dat hoewel auditieve feedback (jezelf horen terwijl je praat) niet nodig is voor het spreken (spraakproductie), incorrecte auditieve feedback wel een hindernis kan zijn. Denk maar een slechte telefoonverbinding waarbij je jezelf met een kleine vertraging hoort: experimenten waarbij je auditieve feedback een kleine vertraging heeft, tonen aan dat dit problemen veroorzaakt bij het praten (haperingen, onderbrekingen, enz.). Auditieve feedback heeft dus wel degelijk invloed heeft op je spraakproductie.
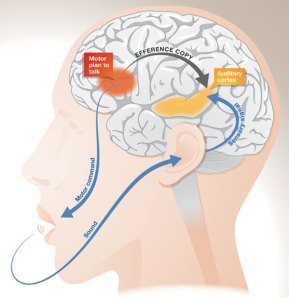
Dr. John Houde heeft in recente jaren een model ontwikkeld van hoe deze auditieve feedback met spraakproductie geïntegreerd wordt in de hersenen. Volgens dit model voorspellen we op het moment dat we onze spraakorganen aansturen om iets te zeggen, ook al meteen intern hoe onze spraak zal gaan klinken. Deze voorspelling van het spraakgeluid wordt in onze hersenen dan vergeleken met het waargenomen spraakgeluid (de feedback). Als de voorspelling en de feedback niet helemaal overeenkomen, hebben we waarschijnlijk een spreekfout gemaakt. In dat geval wordt er een signaal naar het motorische centrum van de hersenen gestuurd, waardoor we de fout snel kunnen rechtzetten. In zijn lezing toonde dr. Houde dat computersimulaties van zijn model resultaten geven die erg lijken op resultaten van zijn experimenten. Zijn model lijkt dus te kloppen!
In enkele van zijn experimenten werd de auditieve feedback van proefpersonen verstoord door er de toonhoogte van te veranderen. Met andere woorden, terwijl proefpersonen spraken, hoorden ze hun eigen stem een halve toon lager via een koptelefoon. De resultaten van het experiment toonden dat proefpersonen als het ware automatisch de verstoorde feedback compenseerden: als hun eigen stem in toonhoogte verlaagd werd, gingen ze met een hogere toonhoogte spreken.
Dit effect kan verklaard worden door het model: de verstoorde feedback zorgt ervoor dat de intern voorspelde toonhoogte niet helemaal overeenkomt met de waargenomen toonhoogte. Dit zorgt voor een signaal naar het motorische centrum in de hersenen, dat de compenserende toonsverhoging veroorzaakt. Dr. John Houde en zijn collega’s voerden dit experiment uit terwijl proefpersonen in de MEG scanner (‘magnetoencephalografie’) lagen. Zo konden ze ook de hersenactiviteit tijdens verstoorde feedback meten. Ze vonden verhoogde hersenactiviteit wanneer auditieve feedback verstoord was. Dr. John Houde denkt dat deze verhoogde activiteit het compensatiesignaal weergeeft dat van het auditieve naar het motorische centrum van de hersenen wordt verstuurd als gevolg van de verstoorde feedback.
Het onderzoek van dr. John Houde en zijn collega’s is erg relevant voor het onderzoek dat in het Neurobiology of Language Departement uitgevoerd wordt. Zo vertelde ik hier al over mijn promotieonderzoek, waarin ik onderzoek hoe mensen kunnen verschillen in dit mechanisme van voorspelling en feedback, en wat dat wil zeggen over hoe goed mensen zijn in het leren uitspreken van nieuwe spraakklanken.
Matthias Franken is promovendus in het Neurobiology of Language department van Peter Hagoort


Plaats een reactie